
Autoscale your Kubernetes Workloads intelligently using Keda

Keda is event driven autoscaler built for Kubernetes
Why autoscaling?
One of the most crucial aspects in application hosting is how it can respond to variable load. During the lifetime of hosted applications, applications experience variability in load due to various reasons like seasonality, marketing events, etc. It is essential that our application can respond to such events successfully, without any impact on its SLA. But it is also not economical to hold huge amounts of hosting resources for seasonal and occasional variables in load. This is where autoscaler comes in. Autoscaler is a component which can trigger scale-up / scale down events in the kubernetes cluster to scale deployment, statefulsets and other such resources.
What are our options for autoscaling?
We can either scale horizontally (add more instances of the application) or vertically (make more resources available to the application). Typically, it’s more complicated to change the available resources for the pod in the kubernetes cluster. It’s quite easier to just scale one more / less replica of the application.
We have below options when it comes to scaling in kubernetes cluster
- Horizontal Pod Autoscaler – HPA is a first class citizen of Kubernetes. You can configure the HPA manually for each application.
- Keda – Keda is a Kubernetes operator for HPA – which adjusts HPA objects based on events. Events can happen within or completely outside the cluster.
- VPA – Vertical Pod Autoscaler – VPA works as an operator which can adjust the requested resources based on actual usage of the application.
- Goldilocks – Goldilocks helps to create VPA easily.
- Cluster Autoscaler – Cluster Autoscaler worker rather at worker node level and helps you create or remove worker nodes depending upon the overall workload in the cluster.
Today, we would see HPA and Keda in depth.
Why Keda over Horizontal Pod Autoscaler?
KEDA is a Kubernetes-based Event Driven Autoscaler. With KEDA, Kubernetes workloads can be autoscaled based on the number of events needing to be processed.
Internally, Keda uses HPA to delegate actual scaling up and scaling down operations. Keda really shines to scale the “processing” jobs based on onslaught of incoming load. E.g. Kafka Queue depth, AWS Kinesis Stream’s shard count, number of files in Azure blob storage. See here for all available Keda scalers. It is easy to also extend and write your own scaler which can react to events of your choice.
Quick start using Keda (show me the money)!
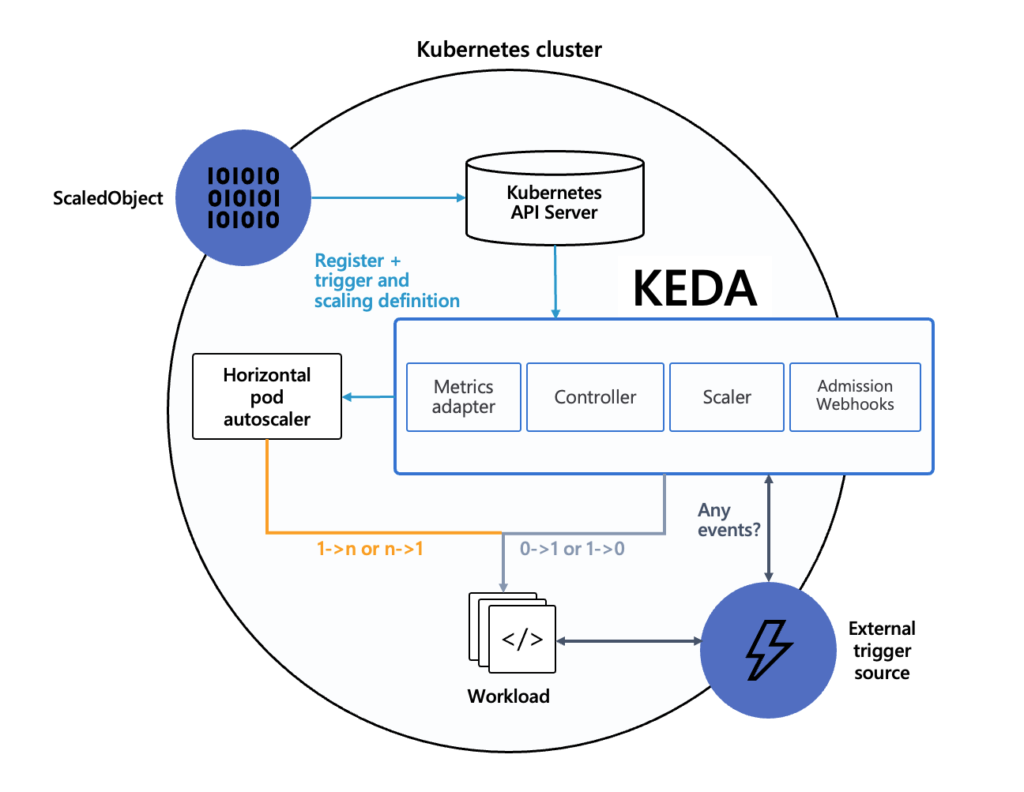
Keda defines a new Kubernetes Custom Resource (CR) – ScaledObject – which maps the Kubernetes Workload which needs to be scaled up/down with external triggers source which will trigger scale up/down.
To demonstrate simple event driven usage of keda – we will be creating a number of files in Azure blob storage. In the example below you will see The ScaledObject definition which will map nginx deployment as target with count of files in Azure Blob Storage as trigger source.
Pre-requisites:
- A kubernetes cluster with supported kubernetes version
- Helm installation
- Azure login with permissions to create storage account and containers. (or just create)
For more updates, follow us on LinkedIn, Twitter, Facebook, Instagram, and YouTube


